
The why.
A surrogate key (SK) is a type of unique identifier for a row in a database which decouples any relations from the source data and becomes the primary identifier in the data warehouse. And in the case of dimensional data modeling they are the foreign keys (FK) in the facts tables. From here on forward – everything is in the context of dimensional data modeling.
It does not necessarily mean they have to be different from the source data primary identifier. Let’s say you have to ELT (extract, load, transform using dbt or other tools) the initial product catalog data from the source where the primary key (PK) is set to auto incrementing INT in an OLTP DB like MySQL. Assuming we will be using “ROW_NUMBER() OVER () AS product_key” to generate surrogate keys for our product dimension – many of them or even all may match depending if there were any hard deletes in the source table and how the source system deals with data updates.
Sounds kind of funny, doesn’t it? Why would you want to do this SK generation stuff at all if there are perfectly fine unique PK’s in the source data? Well, SK’s play a big part in what is called a Slowly Changing Dimension (SCD).
SCD’s are dimensions that hold values (rows/records) which change over time. There are three main types of SCD’s:
- Type 1 – overwrite the original attribute(s) with new ones. No historical tracking. For this type SK’s might have no benefit.
- Type 2 – adding a new record for each change. If implemented correctly, it allows in-depth historical tracking of the changes. Having SK’s in such dimensions can simplify querying and materializing the facts table.
- Type 3 – adding a new column per change. This type of SCD holds a limited history (2 or more versions) and can become an ugly monster to deal with in wide dimensions. As there are no new records created in this type of SCD – SK’s might not have any benefit, too!
Now that we know more about SCD’s it becomes more obvious that it is most relevant for SCD Type 2. But still, why? Here’s a simple example of a star schema with a facts table and some dimensions to support it.
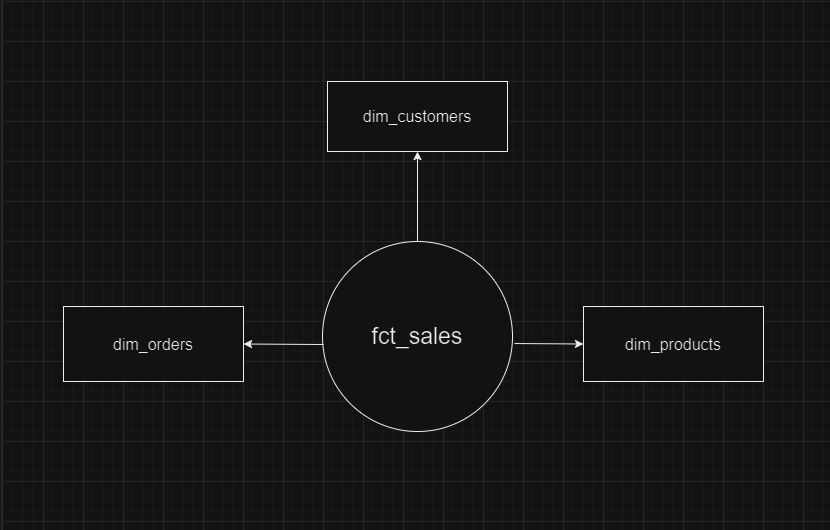
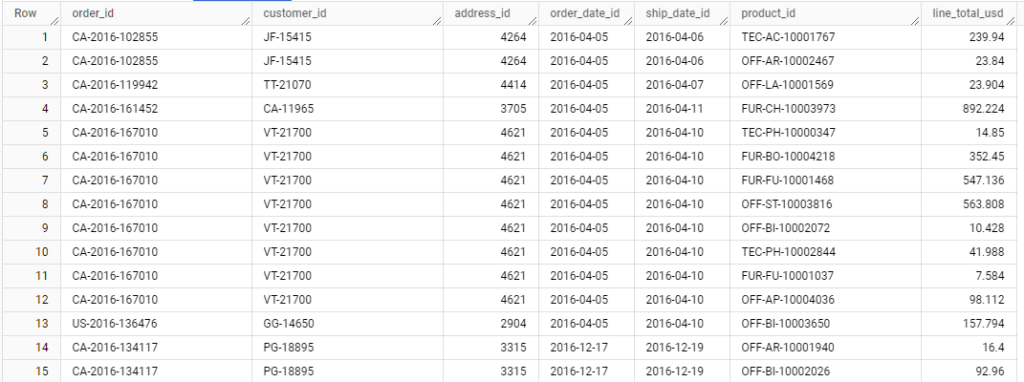
For now there are no SK’s in the dimensions and the facts table holds system PK’s as FK’s to point to the dimensions, like this (you can ignore other dimensions for the purpose of the example):
And the customers dimension looks like this:
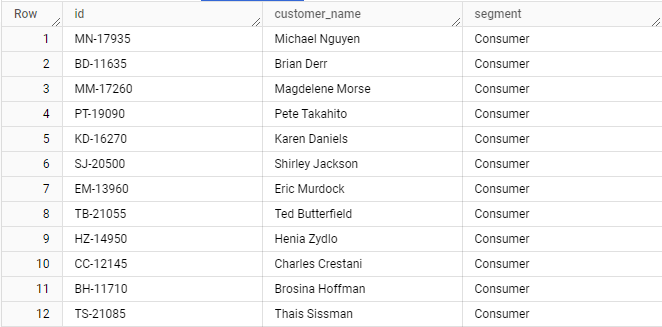
Here the “id” column holds PK’s that come from the source data. And all in all this is perfectly fine and easy to do joins and query data with Type 1 or Type 3 SCD.
But think about what would happen in Type 2 SCD when, let’s say, a “customer_name” or “segment” gets updated? You add a new row with updated values but now there are two rows with the same “id” which introduces inconsistency! This is why having SK’s are important but they alone don’t solve historical tracking problems, more on that later. Additionally, you still want to keep the PK (“id”) but only as a descriptive attribute in order to have an easy way to compare against subsequent data loads and to run some queries, for example when checking sales per product. Even though some attributes of the product change over time (name, category, price, etc) there may be a need to group the results throughout the history of the product changes and the “id” might be the only attribute that achieves it.
The when.
Let’s imagine you are building a simple ELT pipeline, and you are the one man army in a small company to deal with it. Your superior has no clue about any of the technical parts and just asks to have data for some dashboards where he could see sales by product at the time being that come from some e-shop system.
During the dimensions design process is the time when you have to settle on SK generation. Even though the end-user (the superior) did not mention anything about historical analysis, you anticipate that the need might arise later or you, on your own accord, decide that there’s more value to be gained from the available and fully (Type 2) tracked historical data. Having SK alone is not really enough for full historical tracking and I will cover it later.
So when do you need SK? When there’s a clear indication or anticipation for a need of Type 2 SCD. Also you’d still want to set SK when source data does not have any single column unique identifiers (ID, UUID, SKU, e-mail, etc.).
Next I will cover some ways of how to implement SK for your dimensions on a high-level as it highly depends per use-case.
The how.
First I have to mention a few possible ways of generating the surrogate keys:
- Sequential INT (1, 2, …, 9999. “ROW_NUMBER()” in BigQuery).
- Hash of attribute columns (MD5, SHA256).
- Generating an UUID (BigQuery has an “GENERATE_UUID()” function for this).
Let’s dive deeper for each of them starting from the simplest – Sequential INT.
The pros of using this method are clear – it’s simple to integrate and should be the most performant way to generate SK’s. On the other hand it’s not the best when it comes to parallel processing and distributed systems and possibly not suitable at all in such cases. Your dbt staging dimension file would look like this:
“-- models/staging_dim_products.sql
WITH raw_data AS (
SELECT
id,
product_name,
price,
-- Other columns
FROM
raw.products
)
SELECT
ROW_NUMBER() OVER () AS key,
id,
product_name,
price,
-- Other columns
FROM
raw_data
“Hashed attribute columns are a way to solve the latter issues, and have consistent length values. It does not come for free though as it’s more computationally expensive so keep that in mind when batch sizes are huge (100+ GB).
Your dbt staging dimension file would look like this:
“-- models/staging_dim_products.sql
WITH raw_data AS (
SELECT
id,
product_name,
price,
-- Other columns
FROM
raw.products
)
SELECT
SHA256(CONCAT(CAST(product_name AS STRING), CAST(category AS STRING), CAST(sub_category AS STRING))) AS key,
id,
product_name,
price,
-- Other columns
FROM
raw_data
““GENERATE_UUID()” is next. It’s almost like a hash but not only the SK are unique on a project scope – they are designed to be globally unique. Performance-wise it should be less expensive than hashing but not as fast as “ROW_NUMBER()”. Also the footprint (length) is bigger.
Your dbt staging dimension file would look like this:
“-- models/staging_dim_products.sql
WITH raw_data AS (
SELECT
id,
product_name,
price,
-- Other columns
FROM
raw.products
)
SELECT
GENERATE_UUID() AS key,
id,
product_name,
price,
-- Other columns
FROM
raw_data
“The choice of SK generation type depends on technical needs and should be made during the design stage of the project.
For the purpose of examples I will choose the simplest solution of Sequential INT surrogate keys and SCD Type 2 tracking.
So we have our dimensions and we have our SK’s that get referenced in the facts table, but how do we really keep track of the historical changes?
For it to work SK’s alone are not enough – they are just one of the “bookkeeping” attributes for the dimension. Along with the SK column you should have at least two date columns, usually named “effective_date_start” and “effective_date_end”.
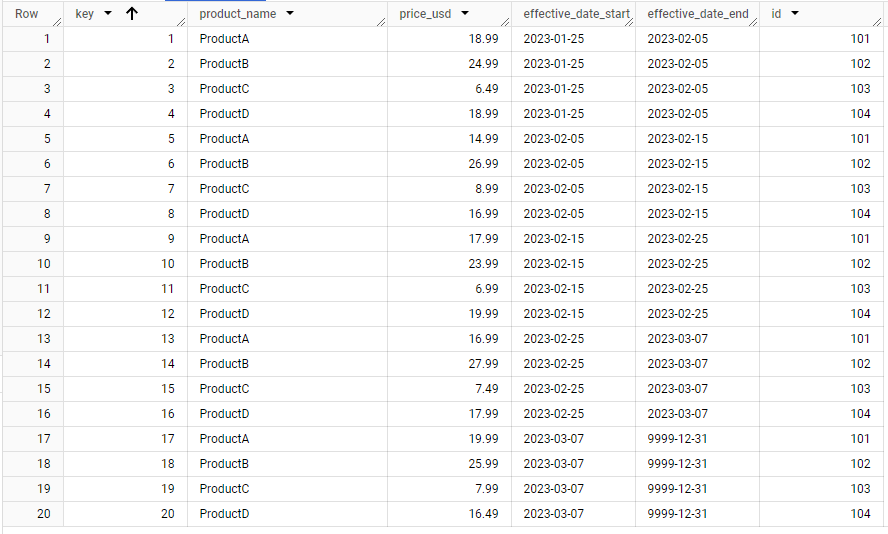
When an updated source row arrives and the comparison is made to the dimension – you have to retire the old row by setting the “effective_date_end” to the time of ingestion, insert the new row with a new SK, set it’s “effective_date_start” to the time of ingestion and set “effective_date_end” to furthest possible date in the future (convention is “9999-12-31”). It is not advised to keep the “effective_date_end” as a “null” value. Optionally it is also possible to have a boolean type column named “current_data” or similar which should also be updated to reflect which row holds the latest data. It simplifies the queries for the analysts to return only the latest records.
When you have these bookkeeping attributes in place you can begin building historical queries, feed the data to dashboards, make reports with Looker studio and so on.
Finishing words.
This is by no means an expert knowledge however I hope you found some of the information useful to help understand the utility of surrogate keys in dimensional data modeling. Excelsior!
Leave a Reply
You must be logged in to post a comment.